

Hedra Labs introducerer realistisk videoavatargenerering fra Audio
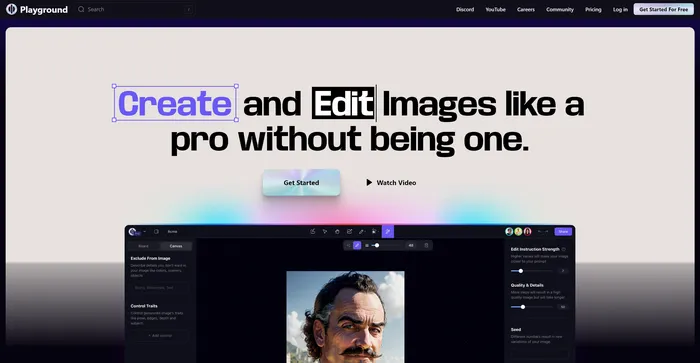
Hedra Labs har afsløret en banebrydende ny model, der er i stand til at generere realistiske videoavatarer udelukkende fra lydindgang. Denne innovative teknologi skubber grænserne for skabelse af virtuel karakter og gør det muligt for brugere at bringe deres historier og ideer ud i livet med hidtil uset lethed.
Alsidige ansigtsgenkendelse og inputmodaliteter
En af de vigtigste styrker ved Hedras model ligger i dens evne til at registrere og generere avatarer fra ansigter i forskellige vinkler, ikke kun direkte billeder. Denne alsidighed giver mulighed for en bredere vifte af inputmuligheder og forbedrer modellens praktiske anvendelighed i virkelige applikationer.
Mens den nuværende version fokuserer på audio-til-video generation, arbejder Hedra Labs aktivt på at udvide modellens muligheder for at understøtte yderligere inputmodaliteter. Denne igangværende udvikling lover yderligere at øge fleksibiliteten og anvendeligheden af teknologien.
Omfattende test med kinesisk og engelsk lyd
Hedras videoavatarmodel har gennemgået strenge tests med begge Kinesisk og engelsk lyd input. Resultaterne har været særligt imponerende for kinesisk lyd, der viser modellens evne til at generere meget realistiske og udtryksfulde avatarer.
Spændende muligheder for fordybende historiefortælling
Introduktionen af Hedras videoavatarteknologi åbner en verden af spændende muligheder for indholdsskabere, undervisere og historiefortællere. Med evnen til at generere naturtro virtuelle karakterer fra lyd alene, kan brugere skabe fordybende oplevelser, engagerende pædagogisk indhold og fængslende fortællinger som aldrig før.