

Hedra Labs Introduces Realistic Video Avatar Generation from Audio
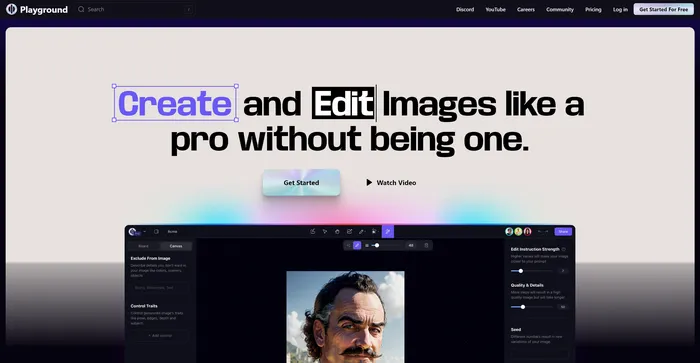
Hedra Labs has unveiled a groundbreaking new model capable of generating realistic video avatars solely from audio input. This innovative technology pushes the boundaries of virtual character creation, enabling users to bring their stories and ideas to life with unprecedented ease.
Versatile Face Detection and Input Modalities
One of the key strengths of Hedra’s model lies in its ability to detect and generate avatars from faces at various angles, not just straight-on shots. This versatility allows for a wider range of input options and enhances the model’s practicality in real-world applications.
While the current version focuses on audio-to-video generation, Hedra Labs is actively working on expanding the model’s capabilities to support additional input modalities. This ongoing development promises to further enhance the flexibility and usability of the technology.
Extensive Testing with Chinese and English Audio
Hedra’s video avatar model has undergone rigorous testing with both Chinese and English audio inputs. The results have been particularly impressive for Chinese audio, showcasing the model’s ability to generate highly realistic and expressive avatars.
Exciting Possibilities for Immersive Storytelling
The introduction of Hedra’s video avatar technology opens up a world of exciting possibilities for content creators, educators, and storytellers. With the ability to generate lifelike virtual characters from audio alone, users can craft immersive experiences, engaging educational content, and captivating narratives like never before.